정형 데이터의 종류와 시각화
데이터 시각화를 하기 전, 기본 문법을 숙지해야 한다.
- 평균비교 - Bar Chart
- 관계표현 - Scatter Plot
- 분포를 나타낼 때 - Histogram, Density Plot
- 데이터의 구성 - Stacked 100% Bar Chart, Pie Chart
DEA를 위해서는 데이터가 가지고 있는 특성을 살펴보고, 이해한 후에 평면적인 데이터에서 주요한 특성을 설득력 있게 드러내는 가장 효과적인 수단이다. 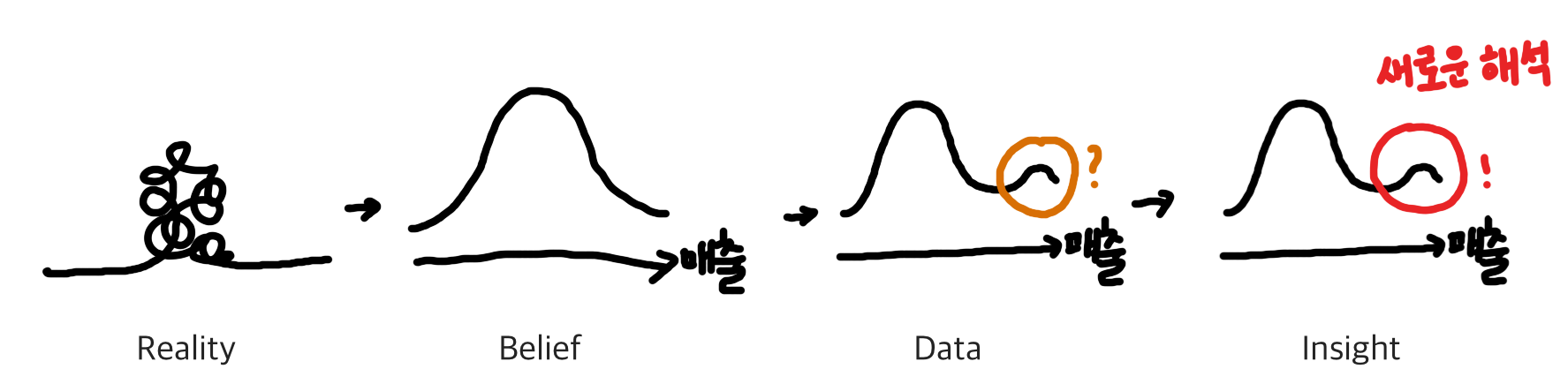
데이터의 종류
정형 데이터는 크게 수치형 데이터, 범주형 데이터로 나뉜다.
수치형 데이터 Numerical Data
- 연속형 Comtinuous Data
- 값이 연속된 데이터
- 키, 몸무게, 수입
- 이산형 Discrete data
- 정수로 딱 떨어져 셀 수 있는 데이터
- 과일 개수, 책의 페이지 수
범주형 데이터 Categorical Data
(범주를 나눌 수 있는 데이터, 사칙연산 불가능)
- 순서형 Ordinal Data
- 순위를 매길 수 있는 데이터
- 학점, 순위
- 명목형 Nominal Data
- 성별, 음식 종류, 우편 번호
수치형 데이터 시각화
수치형 데이터는 일정한 범위 내에서 어떻게 분포되어 있는지가 중요하다. 분포가 고르게 퍼져있을 수도, 특정 영역에 몰려 있을 수도 있다.
분포를 나타내는 “확률밀도함수”는 Unimodeal(단봉 분포)와 Bimodal(쌍봉 분포)가 있는데 쌍봉 분포는 서로 다른 특성을 갖는 두 개의 집단에 표본이 존재함으로 새로운 해설을 도출 수 있다.
Seaborn에서 제공하는 주요 분포도 함수
- histplot(): 히스토그램 (구간별 빈도수)
- kdeplot(): 커널밀도추정 함수 그래프
- displot(): 분포도 (수치형 데이터 하나의 분포를 나타냄, kaggle에서 많이 씀)
- rugplot(): 러그플롯 (주변 분포를 나타냄, 다른 분포도와 사용)
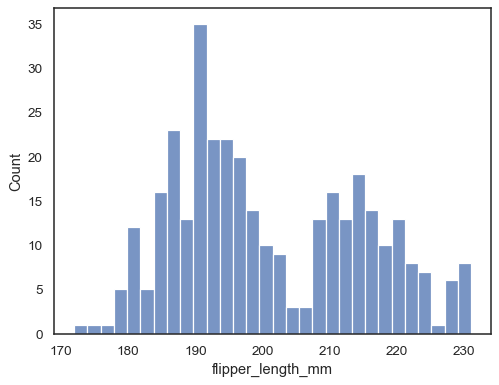
히스토그램
1
2
# hisplot
sns.histplot(data=penguins, x="flipper_length_mm", bins=30)
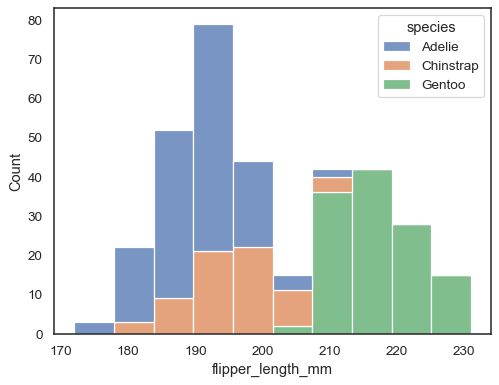
 그래프를 포개지 않고 표현하려면 multiplot=’stack’을 전달한다.
그래프를 포개지 않고 표현하려면 multiplot=’stack’을 전달한다.
1
2
# hisplot
sns.histplot(data=penguins, x="flipper_length_mm", hue="species", multiple="stack")
커널밀도 추정 함수 그래프
커널밀도추정이 무엇인지 이해하려면 밀도추정과 커널 함수에 대해 알아야 하지만, 히스토그램에 비교해보면 좀더 매끄럽게 연결되고, 연속적이다.
1
2
# kdeplot
sns.kdeplot(data=tips, x="total_bill", hue="time", multiple="stack")
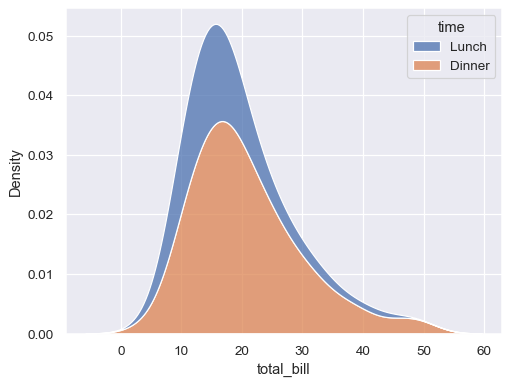
분포도
수치형 데이터 하나의 분포를 나타내는 그래프이다. 캐글에서 분포도를 그릴 떄 displot()을 많이 사용한다. 파라미터만 조정하면 히스토그램, 커널밀도추정 함수 그래프를 모두 그릴 수 있다.
1
2
# displot
sns.displot(df["flipper_length_mm"], kind="kde")
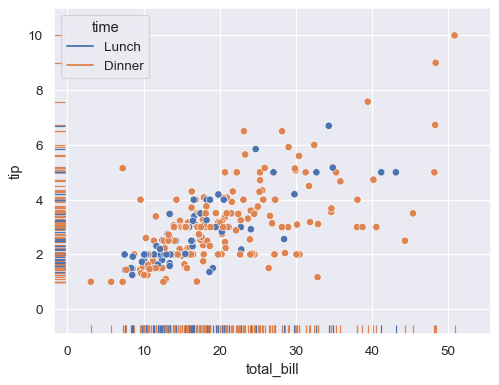
러그플롯
피처가 어떻게 분포되어 있는지 작은 선분(러그)으로 표시한다.
1
2
3
# rugplot
sns.scatterplot(data=tips, x="total_bill", y="tip", hue="time")
sns.rugplot(data=tips, x="total_bill", y="tip", hue="time")
범주형 데이터 시각화
Seaborn에서 제공하는 함수
- barplot(): 막대 그래프
- 범주형 데이터 값에 따라 수치형 데이터 값이 어떻게 달라지는지 파악
- 신뢰구간은 오차 막대 error bar 로 표현
- pointplot(): 포인트플롯
- 범주형 데이터에 따른 수치형 데이터의 평균과 신뢰구간을 나타냄
- 한 화면에 여러 그래프를 그릴 때 쓰임
- boxplot(): 박스플롯
- 막대 그래프나 포인트플롯보다 더 많은 정도
- 구체적으로 5가지 요약 수치를 제공
- violinplot(): 바이올린플롯
- 박스플롯 + 커널밀도함수
- conutplot(): 카운트플롯 (범주형 데이터의 개수 확인)
matplotlib에서만 제공하는 파이 그래프
- pie(): 파이 그래프
막대 그래프
범주형 데이터에 따른 수치형 데이터의 평균과 신뢰구간을 그려준다.
1
2
# barplot
sns.barplot(data=df, x="island", y="body_mass_g", errorbar="sd")
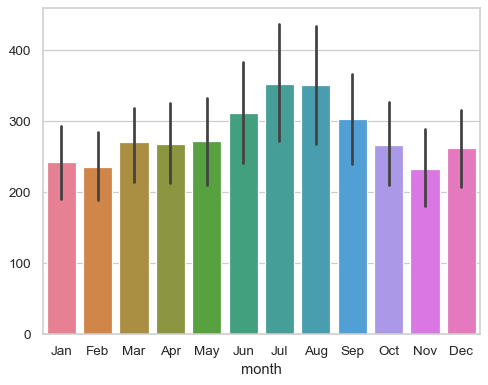 barplot()으로는 평균이 아닌 중앙값, 최댓값, 최솟값을 구할 수도 있다.
barplot()으로는 평균이 아닌 중앙값, 최댓값, 최솟값을 구할 수도 있다.
- estimator: string or callable that maps vector -> scalar, optional
- Statistical function to estimate within each categorical bin.
estimator=np.median, np.max, np.min
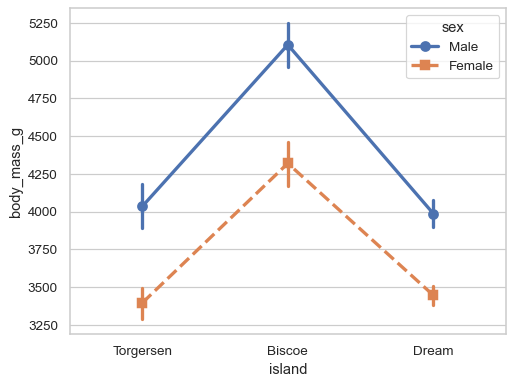
포인트플롯
막대 그래프와 동일한 정보를 제공한다. 한 화면에 여러 그래프를 그릴 때 포인트플롯을 사용하면 가독성있게 한눈에 들어온다.
1
2
# pointplot
sns.pointplot(data=df, x="sex", y="bill_depth_mm", hue="island", dodge=True)
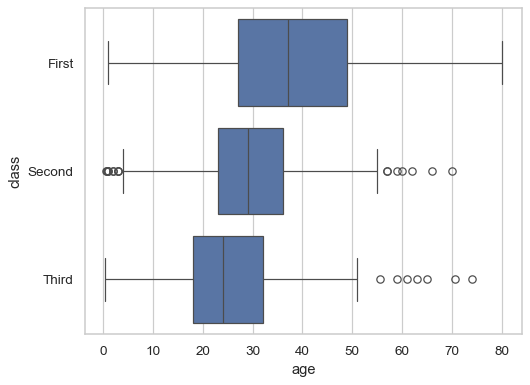
박스플롯
5가지 요약 수치를 제공한다.
- 최솟값
- 제1사분위 수(Q1)
- 제2사분위 수(Q2)
- 제3사분위 수(Q3)
- 최댓값
1
2
# boxplot
sns.boxplot(data=df, x="age", y="class")
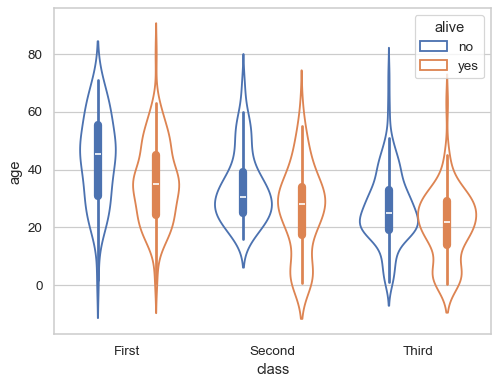
바이올린플롯
박스플롯과 커널밀도추정 함수 그래프를 합쳐 놓은 그래프다. split=True를 전달하면 hue에 전달한 피처를 반으로 나누어 보여준다.
1
2
# violinplot
sns.violinplot(data=df, x="deck", y="age", hue="alive", split=True)
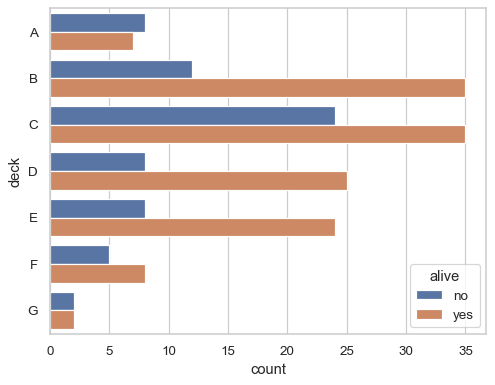
카운트플롯
범주형 데이터의 개수를 확인할 때 사용하는 그래프이다. 주로 범주형 피처나 범주형 타깃값의 분포가 어떤지 파악하는 용도로 사용한다. 범주형 데이터 개수가 많을 때 x와 y의 축 방향을 바꿀 수 있다.
1
2
# countplot
sns.countplot(data=df, y="deck", hue="alive")
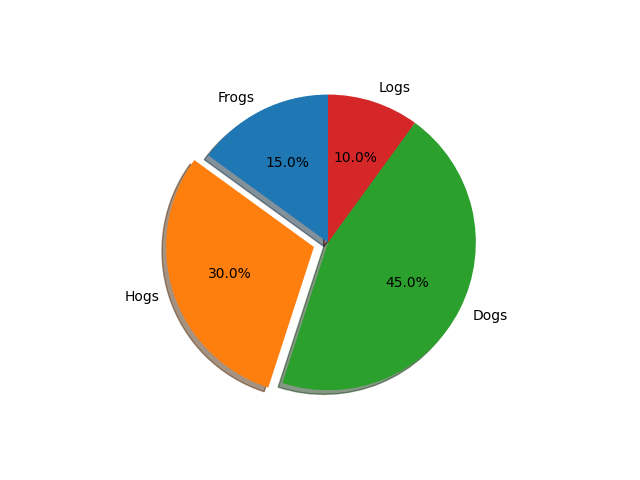
파이 그래프
평균을 비교하거나 범주형 데이터별 비율을 알아볼 떄 사용하기 좋은 그래프다. autopct 파라미터를 통해 비율을 숫자로 나타낼 수 있다.
1
2
3
4
5
6
explode = (0, 0.1, 0, 0) # only "explode" the 2nd slice (i.e. 'Hogs')
fig, ax = plt.subplots()
ax.pie(sizes, explode=explode, labels=labels, autopct='%1.1f%%',
shadow=True, startangle=90)
plt.show()