Stremlit이란?
데이터 과학자들이 데이터 시각화, 머신러닝 모델링, 웹 애플리케이션 등을 쉽게 만들 수 있도록 도와주는 오픈소스 라이브러리이다. Streamlit을 사용하면 파이썬 코드만으로 웹 애플리케이션을 만들 수 있어서, 데이터 분석과 모델링 결과를 공유하거나 인터랙티브한 대시보드를 만드는 등 다양한 용도로 활용할 수 있다. 애플리케이션은 웹 브라우저에서 실행되며, 파이썬 코드와 함께 작동하기 때문에 개발자들이 쉽게 웹 애플리케이션을 구축할 수 있다.
간단한 사용법 알아보기
1
2
3
4
# app.py
import streamlit as st
st.title("Hello world")
터미널에서 아래의 코드를 입력하면 다음과 같이 로컬호스트 서버가 실행된다.
1
streamlit run app.py
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://192.168.0.5:8501
streamlit은 markdown 문법을 지원한다.
1
2
3
4
5
6
7
8
9
10
# app.py
import streamlit as st
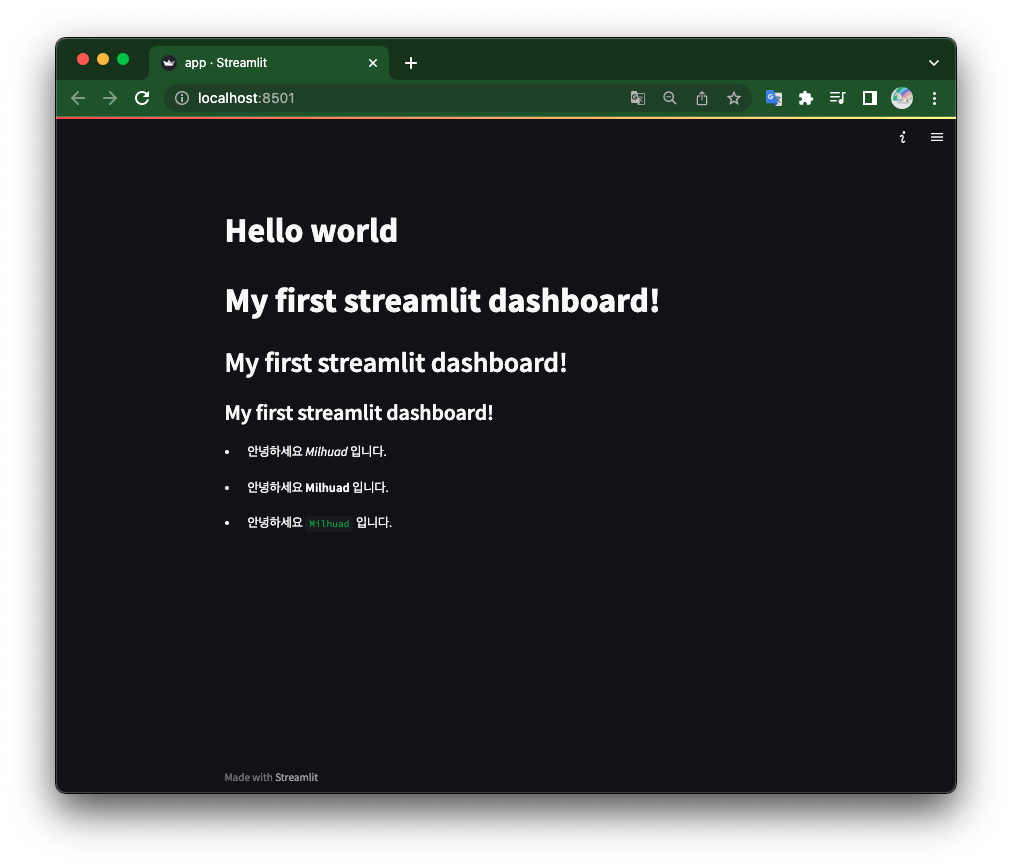
st.title("Hello world")
st.markdown("# My first streamlit dashboard!")
st.markdown("## My first streamlit dashboard!")
st.markdown("### My first streamlit dashboard!")
st.markdown("* 안녕하세요 _Milhuad_ 입니다.")
st.markdown("* 안녕하세요 **Milhuad** 입니다.")
st.markdown("* 안녕하세요 `Milhuad` 입니다.")
Task 1
Crime Data from 2020 to Present 로드하기
- 데이터프레임의
date_rptd컬럼을 pop part 해서 pandas의 date/time 형식으로 변환한다. - 경도와 위도의 결측값은 3차원 지도 시각에서 깨질 것이기에
dropna한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
import streamlit as st
import pandas as pd
import numpy as np
# API Endpoint
DATA_URL = (
"https://data.lacity.org/resource/2nrs-mtv8.csv?$query=SELECT%0A%20%20%60dr_no%60%2C%0A%20%20%60date_rptd%60%2C%0A%20%20%60date_occ%60%2C%0A%20%20%60time_occ%60%2C%0A%20%20%60area%60%2C%0A%20%20%60area_name%60%2C%0A%20%20%60rpt_dist_no%60%2C%0A%20%20%60part_1_2%60%2C%0A%20%20%60crm_cd%60%2C%0A%20%20%60crm_cd_desc%60%2C%0A%20%20%60mocodes%60%2C%0A%20%20%60vict_age%60%2C%0A%20%20%60vict_sex%60%2C%0A%20%20%60vict_descent%60%2C%0A%20%20%60premis_cd%60%2C%0A%20%20%60premis_desc%60%2C%0A%20%20%60weapon_used_cd%60%2C%0A%20%20%60weapon_desc%60%2C%0A%20%20%60status%60%2C%0A%20%20%60status_desc%60%2C%0A%20%20%60crm_cd_1%60%2C%0A%20%20%60crm_cd_2%60%2C%0A%20%20%60crm_cd_3%60%2C%0A%20%20%60crm_cd_4%60%2C%0A%20%20%60location%60%2C%0A%20%20%60cross_street%60%2C%0A%20%20%60lat%60%2C%0A%20%20%60lon%60")
st.title("Incidents of crime in the City of LA")
st.markdown("Streamlit dashboard를 이용한 LA의 범죄 사건 Application 🚗💥")
# row개수에 따라 데이터 보여주기
@st.cache(persist=True)
def load_data(nrows):
data = pd.read_csv(DATA_URL, nrows=nrows, parse_dates=['date_rptd'])
data = data.dropna(subset=['lat', 'lon'])
lowercase = lambda x: str(x).lower()
data = data.rename(lowercase, axis='columns')
data = data.sort_values(by='date_rptd', ascending=False)
return data
data = load_data(100000)
if st.checkbox("Show Raw Data", False):
st.subheader('Raw Data')
st.write(data)
체크박스 유무에 따라 데이터 프레임을 보여준다. 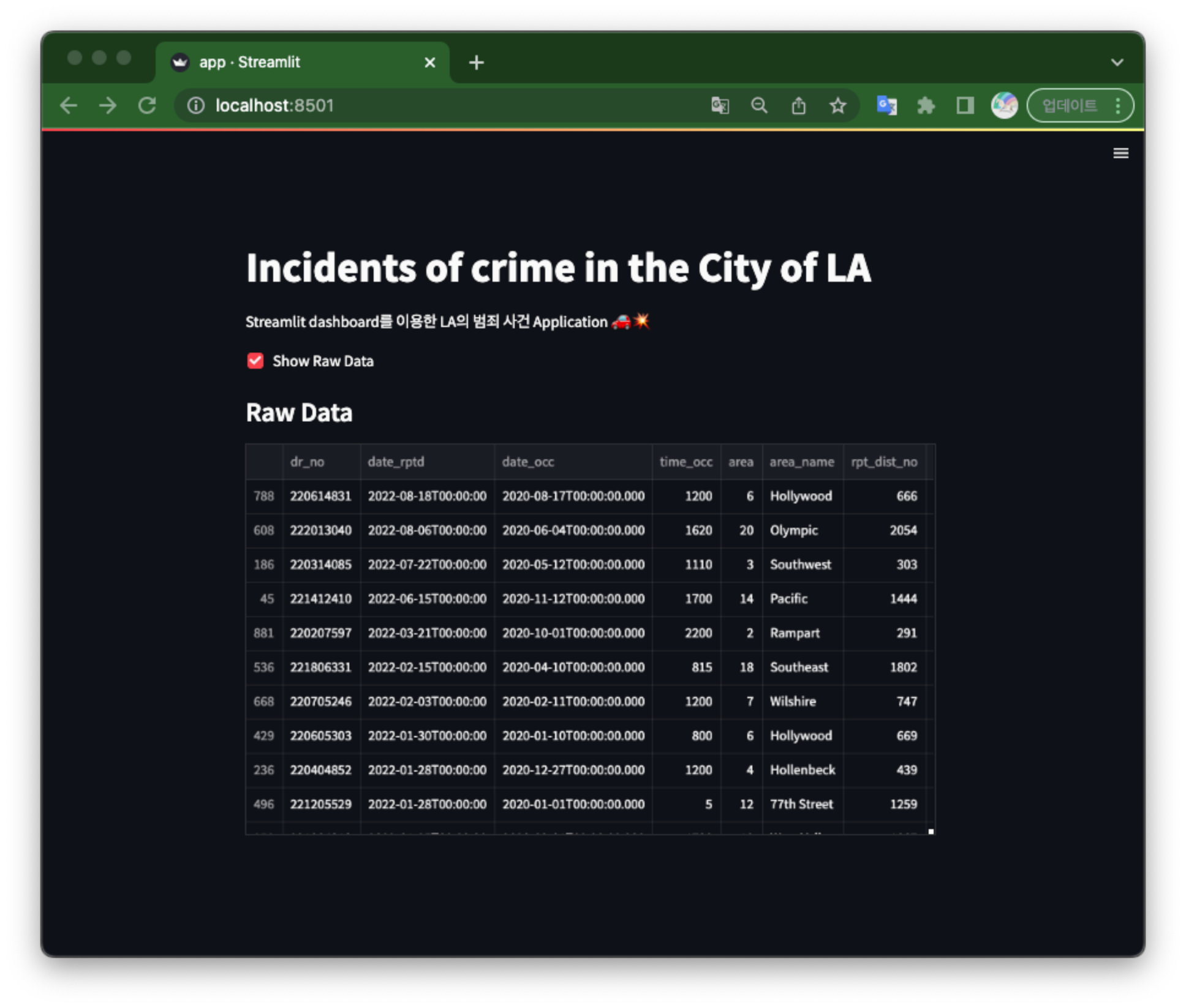
Task 2
데이터 지도 시각화하기
1
2
3
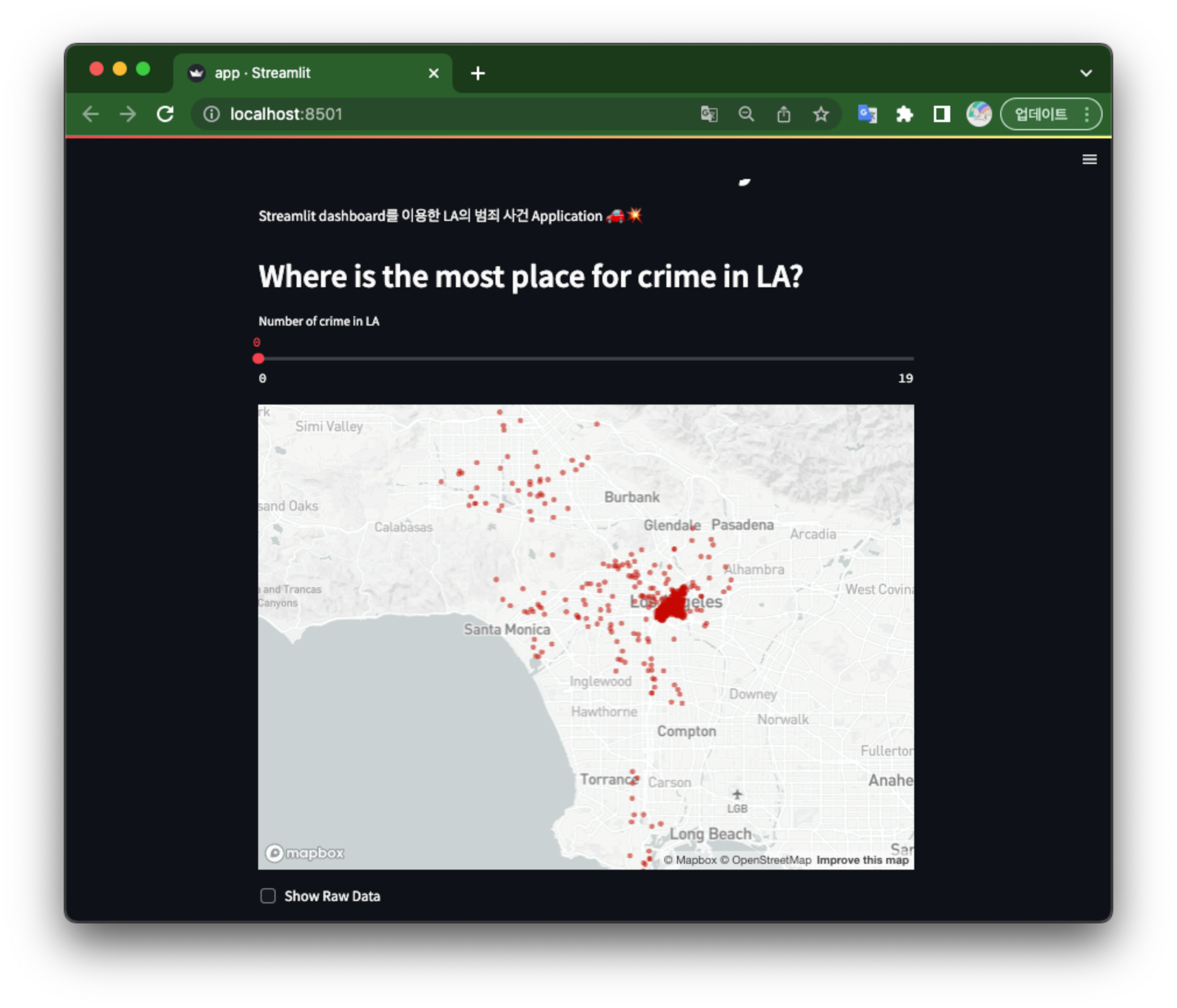
st.header("Where is the most place for crime in LA?")
crime = st.slider("Number of crime in LA", 0, 19)
st.map(data.query("area >= @crime")[['lat', 'lon']].dropna(how='any'))
Task 3
- 데이터 필터링, 인터렉티브 테이블
- 3D 인터렉티브 맵 위에 전처리한 데이터 Plot 그리기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
import pydeck as pdk
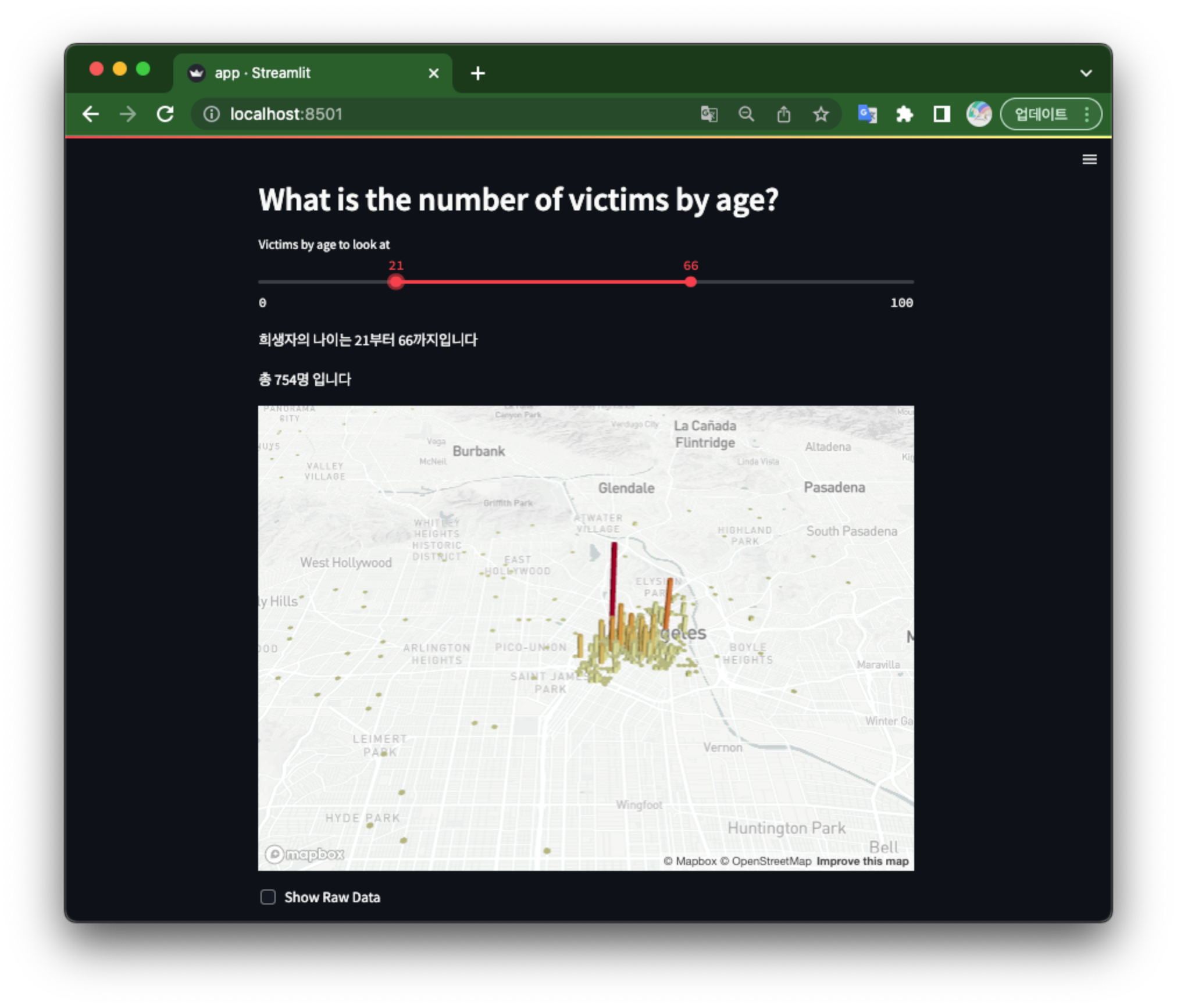
st.header("What is the number of victims by age?")
age_range = st.slider("Victims by age to look at", 0, 100, (0, 100))
data = data[(data['vict_age'] >= age_range[0]) & (data['vict_age'] <= age_range[1])]
st.markdown("희생자의 나이는 %i부터 %i까지입니다" % (age_range[0], age_range[1]))
st.markdown("총 %i명 입니다" % len(data))
midpoint = (np.average(data['lat']), np.average(data['lon']))
st.write(pdk.Deck(
map_style="mapbox://styles/mapbox/light-v9",
initial_view_state={
"latitude": midpoint[0],
"longitude": midpoint[1],
"zoom": 11,
"pitch": 50,
},
layers=[
pdk.Layer(
"HexagonLayer",
data=data[['vict_age', 'lat', 'lon']],
get_position=['lon', 'lat'],
radius=100,
extruded=True,
pickable=True,
elevation_scale=4,
elevation_range=[0, 1000],
),
],
))
Task 5
- 차트 그리기
- 데이터 프레임 정의하기
- groupby로 count할 데이터 그룹핑하기
- plotly express bar로 count bar plot 그리기
1 2 3 4 5 6 7 8 9 10 11
st.subheader("The number of victims by descent and sex") chart_data = pd.DataFrame({ 'crime_cd': data['crm_cd'], 'type': data['crm_cd_desc'], 'descent': data['vict_descent'], 'sex': data['vict_sex'], }) chart_data = chart_data.groupby(by=['descent', 'sex']).size().reset_index(name='counts') fig = px.bar(chart_data, x='descent', y='counts' , color='sex', barmode='group', height=800) # fig.update_layout(yaxis={'categoryorder':'total ascending'}) st.write(fig)
![streamlit_loaddata]()
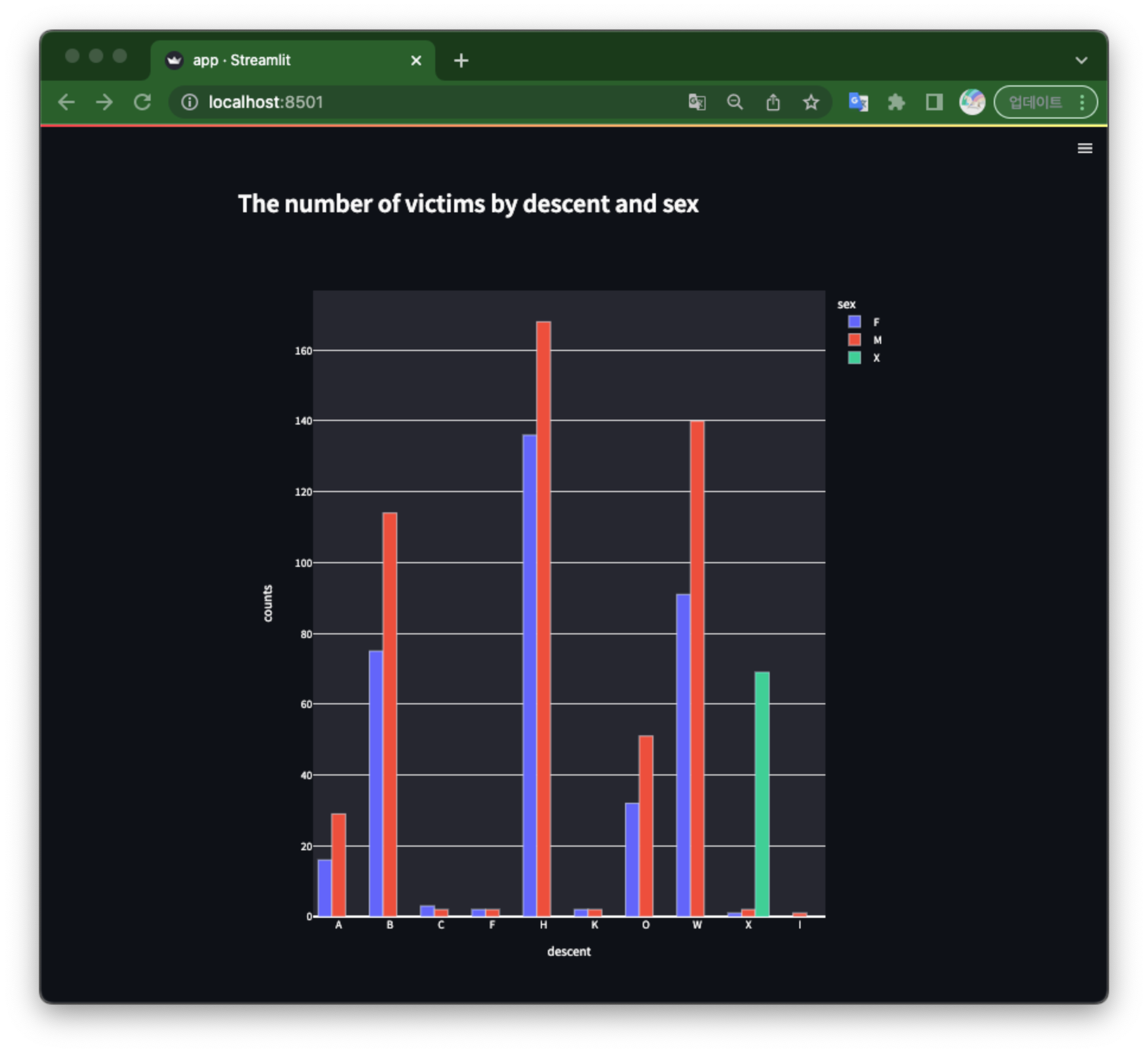
Task 6
드롭 다운을 사용하여 데이터 선택하기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
st.header("Top 5 type of crimes")
select = st.selectbox('The types of crimes & area',
['Vehicle - Stolen', 'Battery - Simple assault', 'Theft of identity', 'Burglary from vehicle', 'Andalism - Felony']
)
if select == 'Vehicle - Stolen':
st.write(data.query("crm_cd_desc == 'VEHICLE - STOLEN'")[["crm_cd_desc", "area_name", "premis_desc"]].sort_values(by=["crm_cd_desc"], ascending=False).dropna(how='any'), width=1000)
elif select == 'Battery - Simple assault':
st.write(data.query("crm_cd_desc == 'BATTERY - SIMPLE ASSAULT'")[["crm_cd_desc", "area_name", "premis_desc"]].sort_values(by=["crm_cd_desc"], ascending=False).dropna(how='any'), width=1000)
elif select == 'Theft of identity':
st.write(data.query("crm_cd_desc == 'THEFT OF IDENTITY'")[["crm_cd_desc", "area_name", "premis_desc"]].sort_values(by=["crm_cd_desc"], ascending=False).dropna(how='any'), width=1000)
elif select == 'Burglary from vehicle':
st.write(data.query("crm_cd_desc == 'BURGLARY FROM VEHICLE'")[["crm_cd_desc", "area_name", "premis_desc"]].sort_values(by=["crm_cd_desc"], ascending=False).dropna(how='any'), width=1000)
elif select == 'Andalism - Felony':
st.write(data.query("crm_cd_desc == 'VANDALISM - FELONY ($400 & OVER, ALL CHURCH VANDALISMS)'")[["crm_cd_desc", "area_name", "premis_desc"]].sort_values(by=["crm_cd_desc"], ascending=False).dropna(how='any'), width=1000)
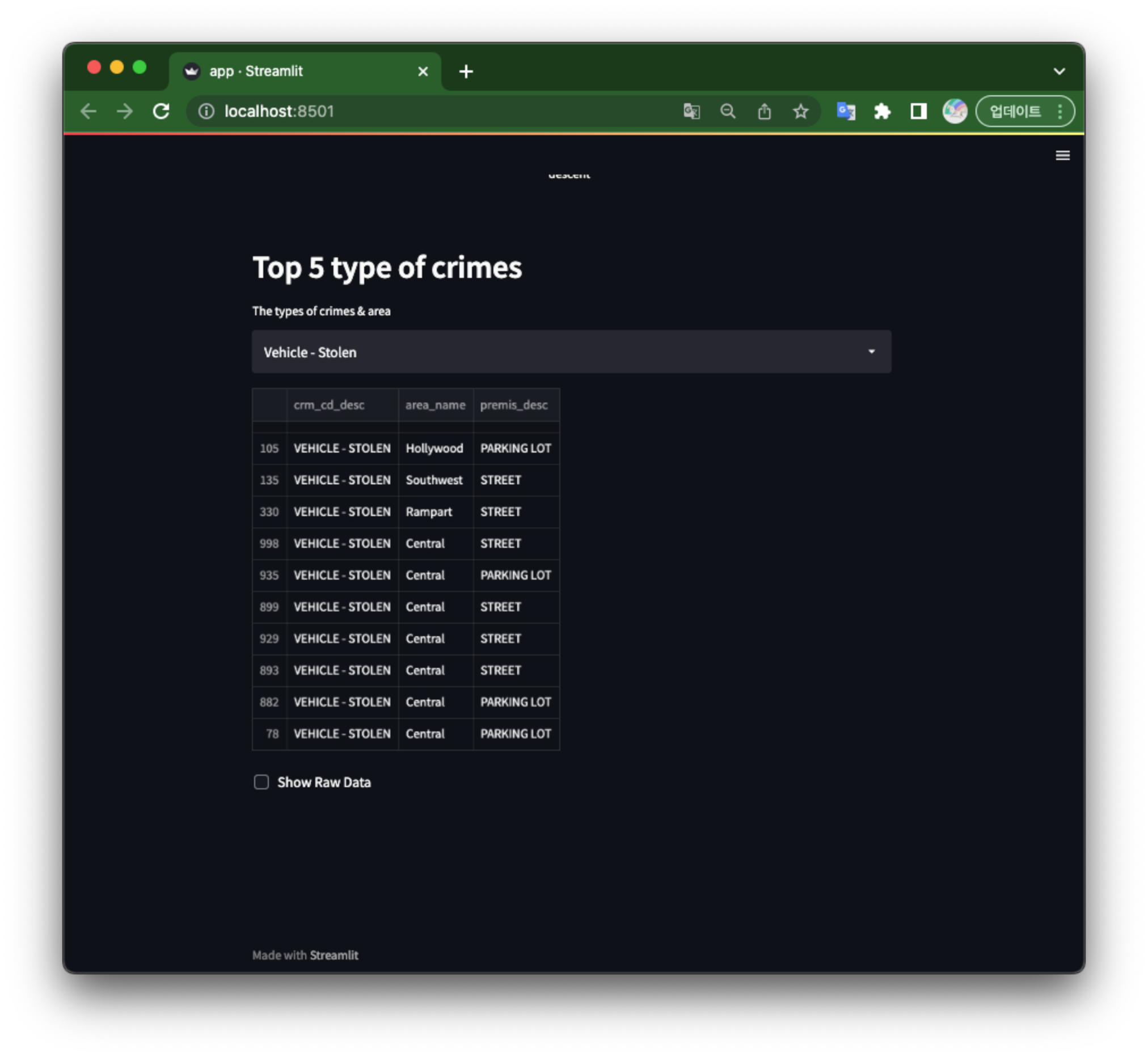
데이터 로드와 간단한 데이터 전처리, 3D 지도 시각화, Bar chart를 그렸다. 본 글에서 데이터 전처리에 대한 디테일은 조금 떨어지지만, 이정도만 알아도 streamlit을 다루기엔 충분하다.
데모 영상과 전체 코드는 여기에 있습니다.
Reference
- Crime Data from 2020 to Present
- Data Provided by Los Angeles Police Department